饱受争议的话题:全局解释器锁 GIL(上篇)

加紧学习,抓住中心,宁精勿杂,宁专勿多。 — 周恩来
引言
有这样一个话题,它对于在 Python 中使用过多线程的开发者来说一定不会陌生。当你遇到它的时候,如果你不了解它的话,很可能你会质疑自己的代码是否具有一些隐藏的问题。在各种社区或论坛中,你也会经常看到关于它的讨论和分析。它便是在当前的 Python 中起到重要作用的全局解释器锁 GIL。在本小节中,我们会从最直观的实例对比中逐步了解 Python 中的 GIL,从多个角度分析它在 Python 实现中的作用和优劣。
全局解释器锁 GIL
什么是 GIL?
全局解释器锁 GIL,英文名称为 Global Interpreter Lock,它是解释器中一种线程同步的方式。对于每一个解释器进程都具有一个 GIL ,它的直接作用是限制单个解释器进程中多线程的并行执行,使得即使在多核处理器上对于单个解释器进程来说,在同一时刻运行的线程仅限一个。
Python 中的 GIL
Python 代码被编译后的字节码会在解释器中执行,在执行过程中,存在于 CPython 解释器中的 GIL 会致使在同一时刻只有一个线程可以执行字节码。
对于 Python 来讲,GIL 并不是它语言本身的特性,而是 CPython 解释器的实现特性。在Python 目前众多的实现中,其中 PyPy 也是具有 GIL 的,Jython、IronPython 中没有 GIL,但这些解释器由于其他原因并未得到广泛使用。同时,其他的编程语言,比如 Ruby 的 C 语言实现中也是具有 GIL 的。
CPython 中的 GIL 导致的问题
GIL 的存在引起的最直接的问题便是:在一个解释器进程中通过多线程的方式无法利用多核处理器来实现真正的并行(对于并行、并发、进程、线程等概念我们在后面的小节中会有更加详细的描述)。对应到真实的业务场景中,在完成一些计算密集型任务时,我们无法通过多线程编程的方式来提高代码的执行效率。
不同类型任务下 GIL 对 Python 多线程的影响
接下来我们就用一些代码实例来验证对 GIL 的描述,上面我们提到了计算密集型任务,这里我简要对比计算密集型任务和 I/O 密集型任务。

计算密集型( CPU-bound ):也称为 CPU 密集型,大部分时间都用于进行计算、逻辑验证等 CPU 处理的程序,比如矩阵计算、视频编解码等,CPU 占用率高。
I/O 密集型( I/O-bound ):大部分时间都用于等待 I/O (比如网络 I/O,磁盘 I/O )处理完成的程序,比如大多数 Web 应用等,CPU 占用率低。
计算密集型任务
首先我们以下面的递增函数为基础对计算密集型任务在 Python 多线程下的表现进行简单的测试。
>>> def loop_add(n):
... i = 0
... while i < n:
... i += 1
...在单线程(即下面运行的主线程)下执行五次( repeat 方法会默认执行 5 次,关于 timeit 模块的更多内容会在后面性能分析相关的小节中描述),执行时间平均值为 3.797136794799735 s。
>>> import timeit
>>> timeit.repeat(stmt="loop_add(100000000)", setup="from __main__ import loop_add", number=1)
[3.824948476998543, 3.784897646999525, 3.7902461680005217, 3.793153800001164, 3.7924378819989215]在下面的函数中开启两个线程分别进行上面单线程中一半数量的递增,在这里注意需要在开启线程后调用 join() 方法来等待线程终止(关于 threading 模块的更多内容会在后面多线程编程相关的小节中描述)。
>>> import threading
>>> def multithread_loop_add():
... t1 = threading.Thread(target=loop_add, args=(50000000,))
... t2 = threading.Thread(target=loop_add, args=(50000000,))
... t1.start() # 启动线程
... t2.start()
... t1.join() # 阻塞直至线程终止
... t2.join()
... 上面的示例在 4 核心 CPU 机器上运行,按照我们预期内的多线程并行执行,两个线程分别执行一半数量递增任务的时间应该为上面单线程执行递增任务时间的 1/2。
>>> timeit.repeat(stmt="multithread_loop_add()", setup="from __main__ import multithread_loop_add", number=1)
[3.9824146000009932, 3.9702273379989492, 3.918540844000745, 3.9172540660001687, 3.8126948980007]但在多线程下执行五次后的执行时间平均值为 3.9202263492003113 s,并不符合我们的预期执行时间。就上面的现象,我们可以从下面两个问题的解答中理解:
为什么执行时间并没有减半?
这正是上面提到的 GIL 导致的结果。由于在同一时刻,即使在多核 CPU 上,也仅有一个线程在获得该全局锁后才可以执行字节码,其他的线程想要执行字节码就需要等待该全局锁被释放,所以未能实现真正的并行执行,而是一种多线程交替执行的串行执行。
为什么在没有减半的基础上,还比单线程执行慢?
因为在多个线程执行过程中也涉及到了全局锁的获取和释放,上下文环境的切换等。并且相较于单核 CPU,这种效率降低的情况在多核 CPU 上在可能会更加显著。
I/O 密集型任务
首先我们以下面的循环网络请求函数为基础对 I/O 密集型任务在 Python 多线程下的表现进行简单的测试。
>>> from urllib import request
>>> def loop_get(n):
... for i in range(n):
... request.urlopen("https://www.imooc.com")
... 在单线程下执行五次,执行时间平均值为 4.795266318800714 s。
>>> timeit.repeat(stmt="loop_get(100)", setup="from __main__ import loop_get", number=1)
[4.631347359998472, 4.591072030001669, 4.871105291000276, 4.901600085002428, 4.9812068280007225]如下面的代码所示,在多线程下执行五次后的执行时间平均值为 2.408049941000354 s。我们可以看到,在 I/O 密集型任务下,Python 多线程的表现是符合我们预期的。
>>> def multithread_loop_get():
... t1 = threading.Thread(target=loop_get, args=(50,))
... t2 = threading.Thread(target=loop_get, args=(50,))
... t1.start()
... t2.start()
... t1.join()
... t2.join()
... >>> timeit.repeat(stmt="multithread_loop_get()", setup="from __main__ import multithread_loop_get", number=1)
[2.389618977002101, 2.4772080140028265, 2.405433809999522, 2.6798762809994514, 2.088112622997869]那么为什么在 I/O 密集型任务下会有这样的效果呢?要回答这个问题,我们需要再对 GIL 更多的细节进行探究。
GIL 全局锁的实现细节
Python 中的线程
Python 使用的是特定于操作系统的线程实现,而并未在解释器中模拟线程。比如在 Linux 系统中,Python 的一个线程对应 Linux 系统中的一个 pthread,其线程调度是交由操作系统本身的调度来完成的。
CPython 中有关 GIL 的一些重要源码
我们在当前版本的 CPython 代码库 中可以找到 ceval_gil.h,它是 GIL 的接口。其中 _gil_runtime_state 可以在 pycore_gil.h 中找到相关定义。
/*
* Implementation of the Global Interpreter Lock (GIL).
*/
static int gil_created(struct _gil_runtime_state *gil)
{
// 省略部分源码
}
static void create_gil(struct _gil_runtime_state *gil)
{
// 省略部分源码
}ceval.c 的主要作用是执行 Python 代码编译后的字节码,在这个文件中我们可以看到在初始化等过程中关于 GIL 的获取和释放:
// 省略部分源码
void
PyEval_InitThreads(void)
{
// 省略部分源码
if (gil_created(gil)) {
return;
}
PyThread_init_thread();
create_gil(gil);
// 省略部分源码
}
// 省略部分源码I/O 密集型任务下的线程切换
在 I/O 密集型任务中,多线程在 GIL 下通常是一种协作式多任务形式。如下图多线程执行中,GIL 会在遇到 I/O 操作时被释放并交由其他线程继续执行,比如网络 I/O 操作、文件读写等。
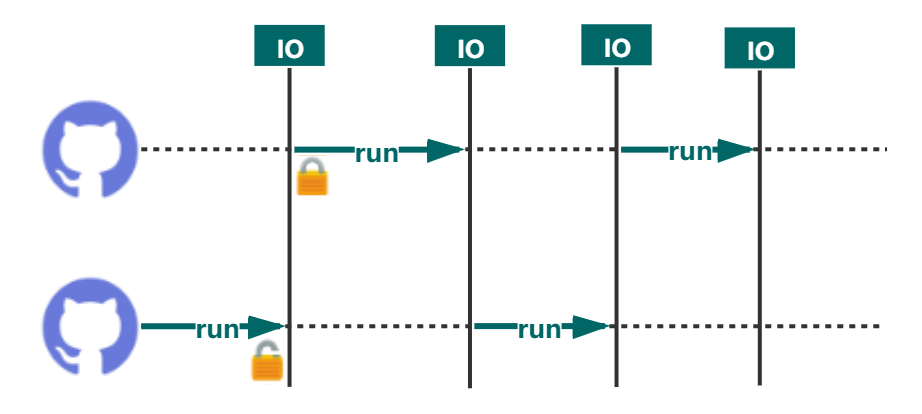
我们继续在源码的基础上理解这种形式,下面的源码来自于 socketmodule.c ,是网络 I/O 中的相关代码,我们可以看到源码中的 Py_BEGIN_ALLOW_THREADS 和 Py_END_ALLOW_THREADS ,这两处便是在网络连接过程中 Python 主动释放和获取 GIL 。这样便回答了上面关于多线程在 I/O 密集型任务下的表现问题,虽然这种形式仍是只有一个线程在执行字节码,但由于等待 I/O 的时间远远大于 CPU 执行时间,仍可通过 GIL 的释放和线程的切换执行来实现并发处理,可以有效的提高执行效率。
static int
internal_connect(PySocketSockObject *s, struct sockaddr *addr, int addrlen, int raise)
{
int res, err, wait_connect;
Py_BEGIN_ALLOW_THREADS
res = connect(s->sock_fd, addr, addrlen);
Py_END_ALLOW_THREADS
if (!res) {
/* connect() succeeded, the socket is connected */
return 0;
}
// 省略部分源码
}计算密集型任务下的线程切换
Python 3.2 之前的 ”基于 opcode 计数“ 机制
那么对于计算密集型任务呢?在计算密集型任务中,如果没有 I/O 相关操作时,还需要一种执行机制来保证 GIL 的释放。在 Python 3.2 之前,CPython 是基于 opcode 执行数量进行周期性间隔检查( Periodic Check )的方式来进行 GIL 的释放和线程切换(我们在前面的小节已经了解了 opcode 的概念,即操作码或操作的数字代码)。如下图所示:
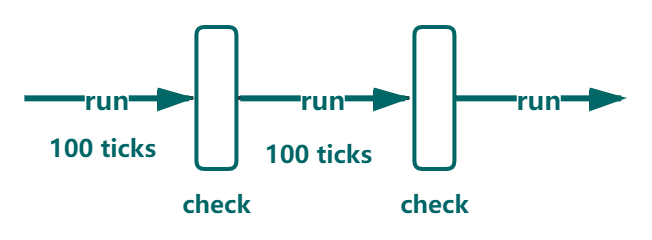
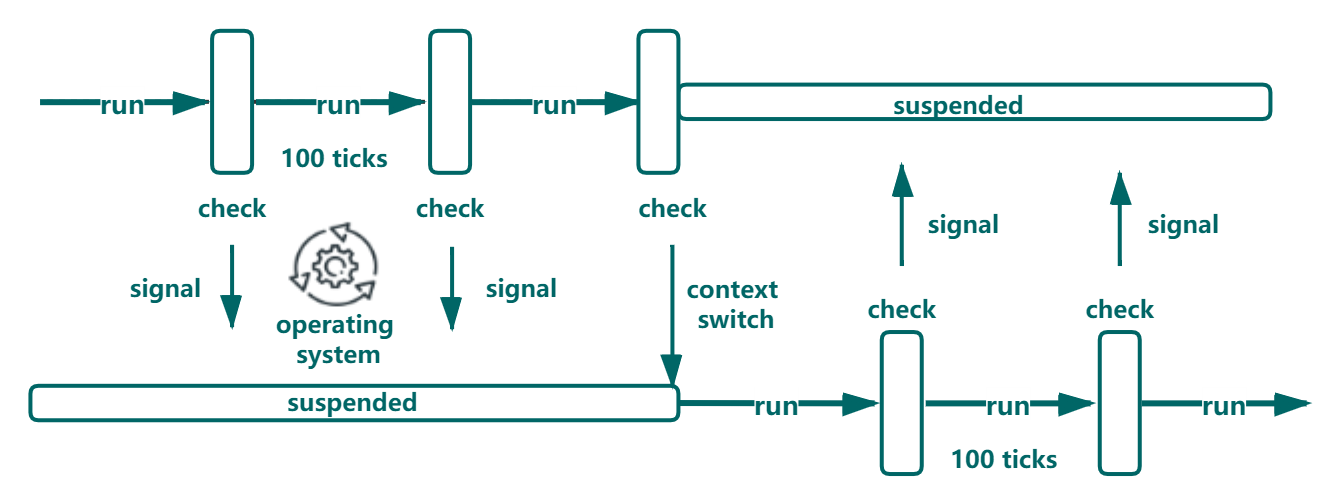
具体地说,当线程在执行时,每经过 “100 ticks” 便主动释放 GIL,此时其他线程便可以获取 GIL 后进行执行。其中 ”tick“ 和时间没有直接关系,它是一个计数器,对应当前线程在两次释放 GIL 之间执行的 opcode 数量,注意这种对应关系并不是每个 opcode 对应一个 ”tick“,有些执行速度快的 opcode 并不会被计入其中,即有可能是多个 opcode 的执行对应一个 “tick”。如下图所示:
这种检查机制时可以通过 sys.setcheckinterval() 和 sys.getcheckinterval() 来设置和查看检查间隔:
>>> sys.getcheckinterval()
100当然,我们之前提到的在 I/O 操作中主动释放 GIL 和间隔检查的机制是结合在一起的,即当遇到 I/O 操作时,即使 tick 计数没有到100 也会主动释放 GIL 。
”基于 opcode 计数“ 机制存在的问题
在 opcode 的执行过程中,“100 ticks” 对应的执行时间是不确定的,有些 opcode 的执行可能相当耗时,这样便导致一些线程的执行时间总是多于其他线程。尤其在多核 CPU 下,运行在不同核心上的线程,一个核心上正在运行执行时间较长的线程时,另外一个核心上的线程可能会多次的抢占 GIL ,导致 CPU 性能没有必要的损耗。
不管是在 I/O 操作时释放GIL,还是在执行了一定 opcode 后释放 GIL,Python 决定的是 GIL 的释放,至于哪个线程会获取到 GIL 并执行是交由操作系统来进行控制的。这样也导致了(尤其在多核 CPU 下),可能存在某些线程刚释放 GIL,又重新获取到 GIL,导致其余 CPU 上的线程反复的从唤醒到等待,造成线程颠簸(thrashing)。
Python 3.2 后 ”基于时间片计数“ 机制
在 Python 3.2 中,GIL 的实现机制发生了一些改变,新的实现机制使用固定的时间间隔来进行线程的切换,在其他线程请求获取 GIL 时,当前运行的线程会以 5 毫秒(默认时间)为间隔尝试释放 GIL。具体的细节可以大体总结为以下三点:
- 基于固定时间而不是一定数量的 opcode 来进行线程切换。
- 当只存在单线程运行时,无需进行相关检查和 GIL 释放。
- 在某个线程释放 GIL 后,需要在其他的线程获取到 GIL 后才能再次进行 GIL 的获取。
新的实现方式解决了之前 GIL 中某线程长时间执行以及 GIL 被某线程释放后又重新获取的问题。并且可以看到在 Python 3.2 后,之前的 sys.setcheckinterval() 和 sys.getcheckinterval()已经不再使用,换为 sys.getswitchinterval() 来查看线程切换时间。可以使用help(sys.getswitchinterval) 来查看对应的文档字符串。
>>> sys.getcheckinterval()
<input>:1: DeprecationWarning: sys.getcheckinterval() and sys.setcheckinterval() are deprecated. Use sys.getswitchinterval() instead.
100
>>> sys.getswitchinterval()
0.005但新的 GIL 实现机制中,线程对 GIL 的获取及执行还是由操作系统完成的,这样仍存在一些效率问题,比如需要被优先执行的某些 I/O 操作的线程可能无法及时获取到 GIL。同时,GIL 对多线程执行的限制这个根本问题还是存在的。