kafka 实战教程
三、kafka的基本知识
1.kafka的安装
-
部署一台zookeeper服务器
-
安装jdk
-
下载kafka 的安装包:http://kafka.apache.org/downloads
-
上传到kafka服务器上:/usr/local/
-
解压压缩包
进入到config目录,修改server.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://172.16.99.3:9092
# A comma separated list of directories under which to store log files
log.dirs=/usr/local/kafka/data/kafka-logs
# Zookeeper connection string (see zookeeper docs for details).
zookeeper.connect=172.16.99.2:2181
- 进入bin目录,执行下面命令启动kafka 服务器
./kafka-server-start.sh -daemon ../config/server.properties
到zookeeper 服务器查看是否启动成功,到zookeeper bin目录
./zkCli.sh
执行下面命令创建名为test 的topic,此topic 只有一个partition,并且备份也设置为1:
./kafka-topics.sh --create --bootstrap-server 172.16.99.3:9092 --replication-factor 1 --partitions 1 --topic test
查看当前kafka内有哪些topic
./kafka-topics.sh --list --bootstrap-server 172.16.99.3:9092
2.kafka 使用
- 发送消息
kafka 自带一个producer命令客户端,可以从本地文件中读取内容,或者我们也可以以命令行中直接输入内容,并将这些内容以消息的形式发送到kafka集群中,默认情况下,每一行会被当做一个独立的消息。使用kafka的发送消息客户端,指定发送到kafka服务器地址和topic
./kafka-console-producer.sh --broker-list 172.16.99.3:9092 --topic test
- 消费消息
对于consumer,kafka同样也携带了一个命令行客户端,会将获取到的内容在命令中进行输出,默认是消费者最新消息,使用kafka的消费者客户端,从指定kafka服务器的指定topic中消息
- 方式一:从最后一条消息的偏移量+1开始消费
./kafka-console-consumer.sh --bootstrap-server 172.16.99.3:9092 --topic test
- 方式二: 从头开始消费
./kafka-console-consumer.sh --bootstrap-server 172.16.99.3:9092 --from-beginning --topic test
- 关于消息的细节
生产者将消息发送给broker, broker会将消息保存到本地的日志文件中
/usr/local/kafka/data/kafka-logs/主体-分区/00000000000000000000.log 比如:/usr/local/kafka/data/kafka-logs/test-0/00000000000000000000.log
消息是有序的,用offset 来描述消息的有序性
消费者消费消息是通过offset来描述当前要消费的消息的位置
- 单播消息
如果多个消费者在同一个消费组里面,那么只有一个消费者可以收到订阅的topic中的消息。
./kafka-console-consumer.sh --bootstrap-server 172.16.99.3:9092 --consumer-property group.id=testGroup --topic test


- 多播消息
# 消费客户端1
./kafka-console-consumer.sh --bootstrap-server 172.16.99.3:9092 --consumer-property group.id=testGroup1 --topic test
# 消费客户端2
./kafka-console-consumer.sh --bootstrap-server 172.16.99.3:9092 --consumer-property group.id=testGroup2 --topic test


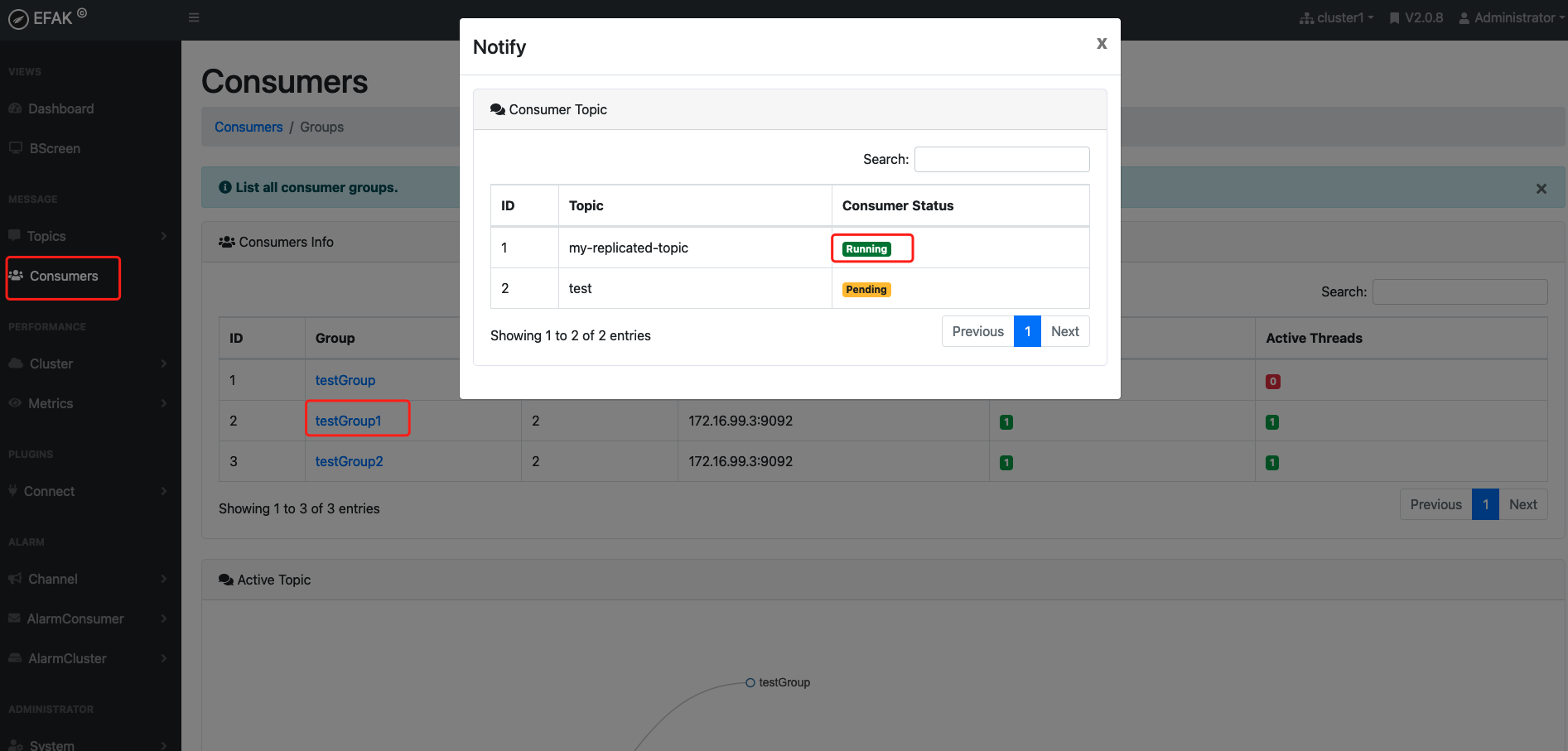
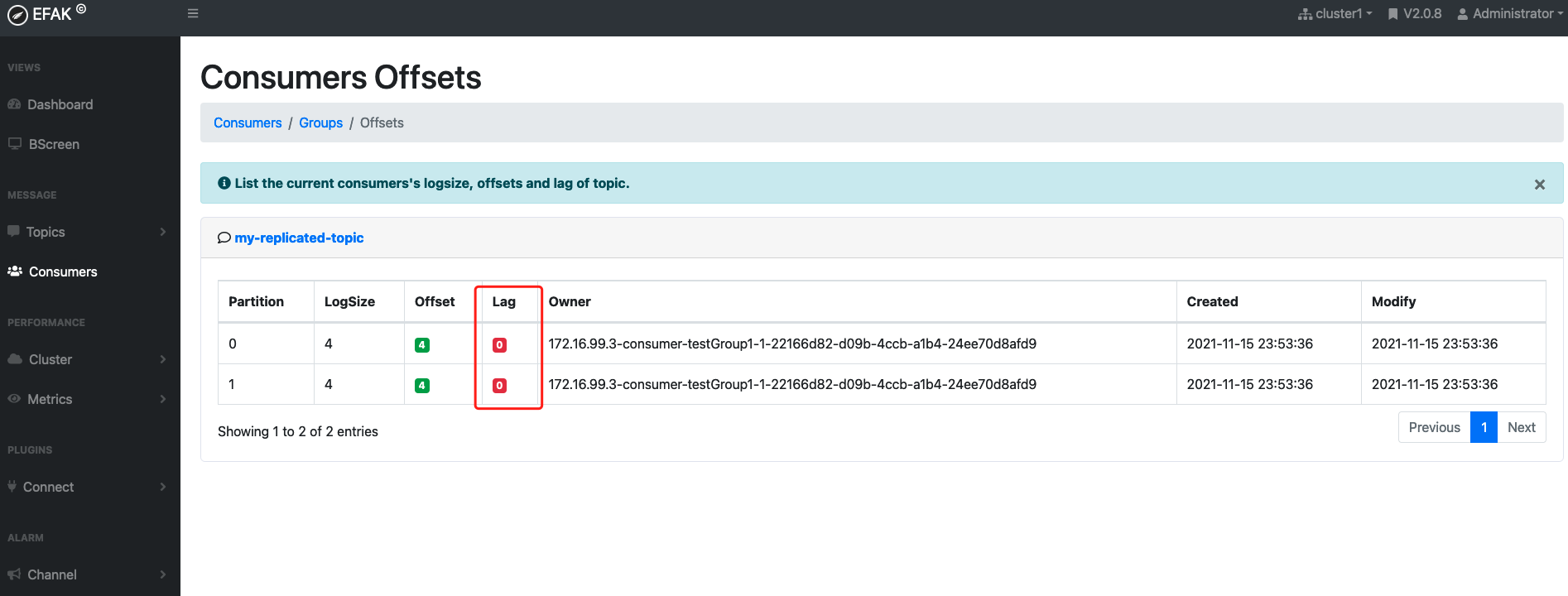
- 查看消息组的详细信息
./kafka-consumer-groups.sh --bootstrap-server 172.16.99.3:9092 --describe --group testGroup
重点关注下面几个信息:
CURRENT-OFFSET:最后被消费的消息的偏移量
LOG-END-OFFSET:消息总量
LAG:积压多少条消息四、kafka中主题和分区的概念
1.主题topic
主题topic 是一个逻辑的概念,kafka通过topic将消息进行分类。不同的topic会被订阅该topic的消费者消费。但是有一个问题,如果这个topic的 消息量特别大,大到几个TB,因为改消息是被存在日志文件中的,后期维护会很困难,为了解决这个问题,kafka提出了partition分区的概念
2.分区partition
通过使用partition的优势:
分区存储,可以解决统一存储文件过大的问题
提供了读写的吞吐量:读和写都可以同时在多个分区中进行- 创建多个分区的主题
./kafka-topics.sh --create --bootstrap-server 172.16.99.3:9092 --replication-factor 1 --partitions 2 --topic test1
五、kafka集群操作
1.搭建kafka集群(三个broker)
- 创建三个server.properties文件
# broker.id 0 1 2 broker.id= 2 # port 9092 9093 9094 listeners=PLAINTEXT://172.16.99.3:9094 # log kafka-logs kafka-logs-1 kafka-logs-2 log.dirs=/usr/local/kafka/data/kafka-logs-2
通过命令启动三个broker
./kafka-server-start.sh -daemon ../config/server.properties
./kafka-server-start.sh -daemon ../config/server1.properties
./kafka-server-start.sh -daemon ../config/server2.properties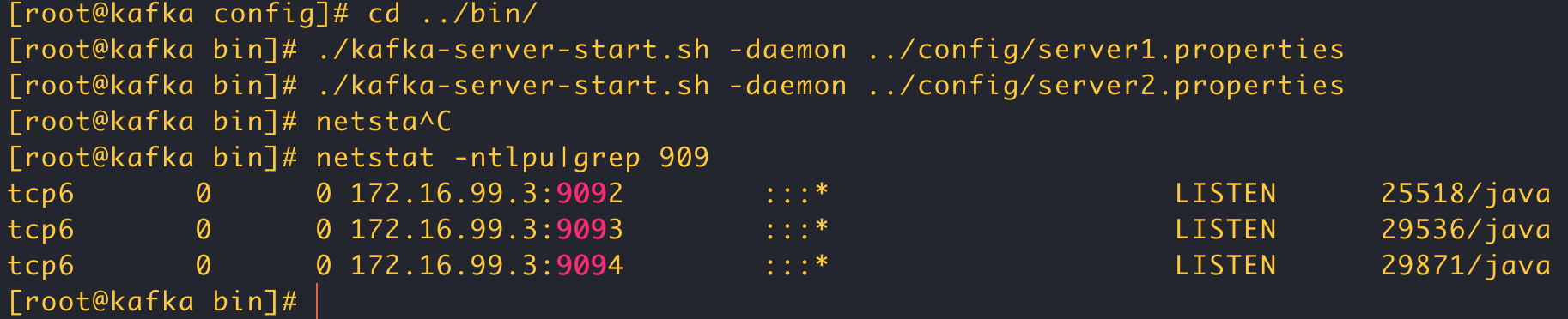

- 副本的概念
在创建主题时,除了指明主题的分区以外,还指明副本数。副本是为了为主题中创建多个备份,多个副本在kafka集群中的多个broker中,会有一个副本作为leader,其他副本为follower。
- 创建多个副本的topic
./kafka-topics.sh --create --bootstrap-server 172.16.99.3:9092,172.16.99.3:9093,172.16.99.3:9094 --replication-factor 3 --partitions 2 --topic my-replicated-topic
- 查看集群的情况
./kafka-topics.sh --describe --bootstrap-server 172.16.99.3:9092,172.16.99.3:9093,172.16.99.3:9094 --topic my-replicated-topic
– 关于集群消费
- 向集群发送消息
./kafka-console-producer.sh --broker-list 172.16.99.3:9092,172.16.99.3:9093,172.16.99.3:9094 --topic my-replicated-topic
- 从集群消费消息
./kafka-console-consumer.sh --bootstrap-server 172.16.99.3:9092,172.16.99.3:9093,172.16.99.3:9094 --from-beginning --consumer-property group.id=testGroup1 --topic my-replicated-topic
如果在同一个消费组启动多个消费者,测试证明默认是轮询消费



六、kafka集群监控
1.搭建kafka-eagle
- 下载
http://download.kafka-eagle.org/
解压后将根目录文件移动到 /usr/local/kafka-eagle 文件夹里
- 添加环境变量到/etc/profile
export KE_HOME=/usr/local/kafka-eagle
export PATH=$PATH:$KE_HOME/bin加载环境变量
source /etc/profile- 配置
vim /usr/local/kafka-eagle/conf/system-config.properties
# zookeeper 配置
efak.zk.cluster.alias=cluster1
cluster1.zk.list=172.16.99.2:2181
# 数据库配置,我这里用sqlite,也可以用mysql
efak.driver=org.sqlite.JDBC
efak.url=jdbc:sqlite:/usr/local/kafka-eagle/db/ke.db
efak.username=root
efak.password=www.kafka-eagle.org- 启动kafka-eagle
./ke.sh start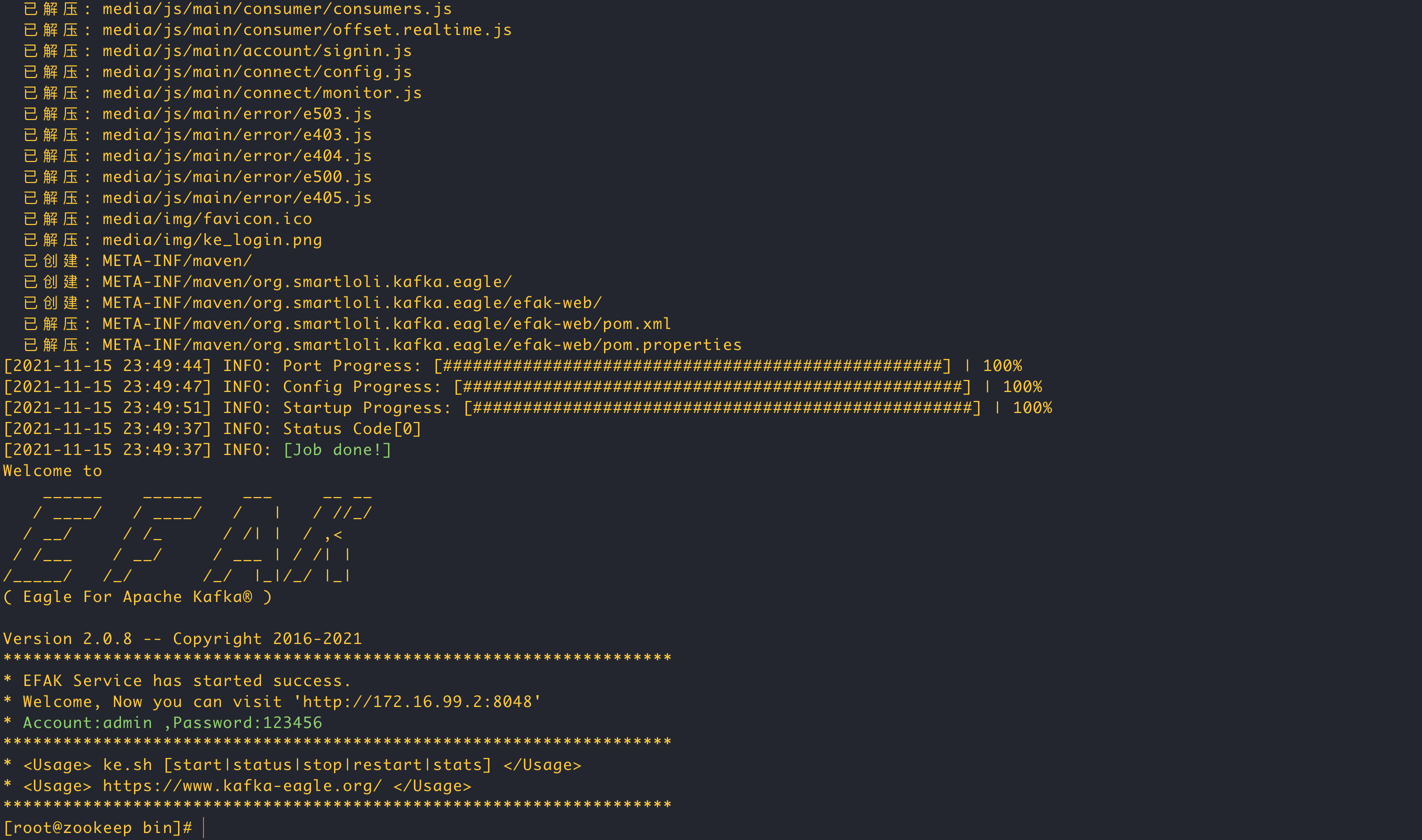
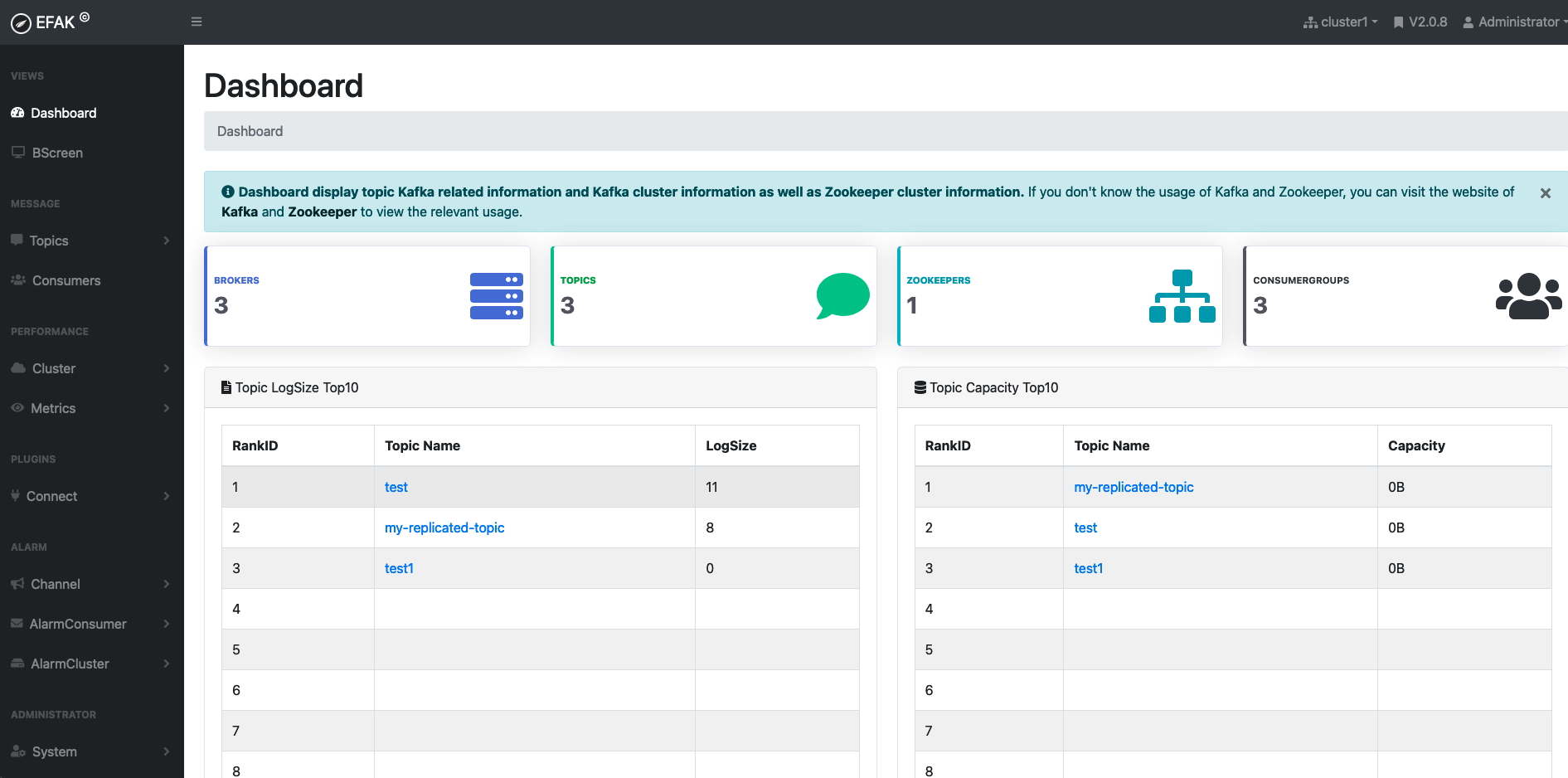
- 查看是否有消息堆积